Letting reinforcement learning agents learn from each other in competitive environments

In the last months I have researched mainly on the basics of AI research and the more precise technologies of reinforcement learning. This led me to my upcoming thesis topic, which tries to let agents learn not only through trial and error but also through observation of other agents. The motivation is embarrassingly simple: I don’t learn about AI by trying different paths in my state space. I take most of what others have developed and researched and basically imitate their behavior. Sometimes I stop reading and start experimenting. But it is certain that I could never learn to become as good with AI as with software development. (My previous field of expertise) by simply doing trial and error or by simply reading. It’s the mix that makes the most sense. The two amplify each other.
The Knowledge Illusion
A great book by Sloman and Fernbach, called *The Knowledge Illusion *inspired me to look at AI research from a different point of view. Whenever we talk about AI, we talk about a single unit. The only exception was Max Tegmark in Life 3.0, but he talked about multiple AGI’s being developed at *roughly the same time. *However, everyone assumes that if we as humans will create AGI, artificial **general **intelligence, we will create one instance of it. Sloman and Fernbach argue however, that humans are not intelligent the way we are because of our individual achievements but because we are a society of intelligent agents. Hence, we are as intelligent as we are today, because we evolved together, as a community of agents. My hypothesis therefore started to slowly form:
Artificially intelligent agents must not necessarily be intelligent on their own but might very well just develop a higher level of intelligence if they get to interact with each other in a manner similar to the way humans interact.
Current state of research
Current AI research mostly trains its agents as if they were single children without friends. When we train an agent, we put them in an environment (often without other agents, sometimes also with other agents) and do cooperative or competitive plays. There’s work on trying to anticipate other agents moves and there is work trying to reach Nash Equilibriums. There is also stuff like “One-Shot Imitation Learning” and the famous Helicopter flying RF agent by Andrew NG which learned from pros like an apprentice. But it doesn’t seem to be an idiom that is omnipresent. It’s a “you can try this once” but not a “agents need to be trained in a social setting”. Yet humans need social interaction to have any chance at developing a healthy, working intellect.
I want to try and let agents observe each other by comparing their performance and when one agent performs much better than the one that is trying to learn, it uses some actions of that agent as a set of input/output labeled examples of “how it is done”.
Let’s compare this to how humans learn: Children watch each other while they play and imitate each others behavior. They also imitate their parents and learn from the results of their newly adopted actions. Children do this less for serious reasons but mostly in a form of play. But the results are the same: Children learn rapidly in their first few years and while it is not simply because they imitate their surroundings, it is surely a mix of the constant trial and error as well as having hundreds of role models surrounding them.

So, why not let reinforcement agents in AI research do the same? If there are other agents like them, let’s observe their performance and if they turn out to be better than our agents, imitating some of their actions might not be such a bad move. This is obviously supervised learning by the book but because the examples stem from another agent acting in an environment autonomously, it’s easy to get them. If I am an agent that is trying to run but I am just started out, instead of trying hundreds of thousands of times to get up and move somehow without ever knowing what the hell I am doing, watching an agent that can already run and trying to imitate him might be a smart move. This even occurs in aforementioned paper called “Emergent Complexity via Multi-Agent Competition”. They need to *retrain *their agents to learn running and walking again before they can start playing football. Previous agents already learned this behavior but these needed to relearn it all from scratch. It’s like reinventing the wheel. And it’s time for some sort of AI agent school where they teach each other some tricks so they don’t all have to do the same all over again.
So let’s dig into the tech:
My agent is a “normal” deep RF learning agent that tries to reach the same goal as another agent. They are in a competitive setting, be that running somewhere, trading electricity in a wholesale market or whatever. The agent does the usual learning, for example using PPO or vanilla policy gradient optimisation. But this is being alternated with a situation where my agent watches the other agent’s state-action pairs and compares its performance against that of the agent.
Here is where I am stuck
Let’s say we have an agent A, let’s call him Chuck Norris, short Norris. And we have agent B, the learning one that is trying to learn both as a deep RF agent and by stealing ideas from others. Let’s call B Bob. Both are in a POMDP.
To learn from Norris, Bob needs
- State s
- Resulting action a
- Resulting State s'
- Resulting Utility U(s')
Now it can feed the state into it’s own policy function and see if the utility is better/worse than that of Norris. Now the …darn… moment: It’s a POMDP! Meaning we have neither the state transition probability of an action nor do we have the assurance that the new state we observe is without noise.
What does this mean? It means, we don’t know if the resulting state s’ came to be because of the action a or because of some other factor that we aren’t aware of. Maybe the probability of state s’ is 0.3 and if we do this same action 100 times, only 30 out of those 100 samples would actually result in state s’. It also means that we don’t know for sure if state s’ is actually the one that Norris ended up in. It could be, that we just *believe *that Chuck is in s’, but it’s actually the state right next to it.
These problems are common to us humans as well. If you compare yourself to someone who won in the lottery, it might seem tempting to say: “Look, he won the lottery, his state s’ has a much higher utility, I should do as he does”. But the other guy might be a complete dimwit, merely having been lucky to win a game that is designed to be a loosing game. Also, you might not be able to put yourself into the same situation as him, because the situation has passed. You can’t imagine you were in his shoes and then check the resulting utility, because the lottery has already been closed.
Two solution approaches
1. You are in control of the environment
Going back to AI research: Let’s say you want to train Bob to walk up to a car and drive it into another city and you have Norris who can already walk. Your agent Bob however, can’t even walk, let alone drive. Instead of making him learn to walk by himself, you can let him watch Norris walk around like a pro.
Simply get the Norris code and the NN weights, toss him in the environment and give Bob the ability to “observe” him. But how do you let him observe the other guy? You don’t need to. Bob doesn’t need to actively observe, you need to merely decide if Bob should learn from Norris. How can you decide that? By letting Bob and Norris try on their own for a while while recording the environment states. Then you flip their positions and see how they fair in *each others shoes, *meaning how they do if they start at each others starting state.
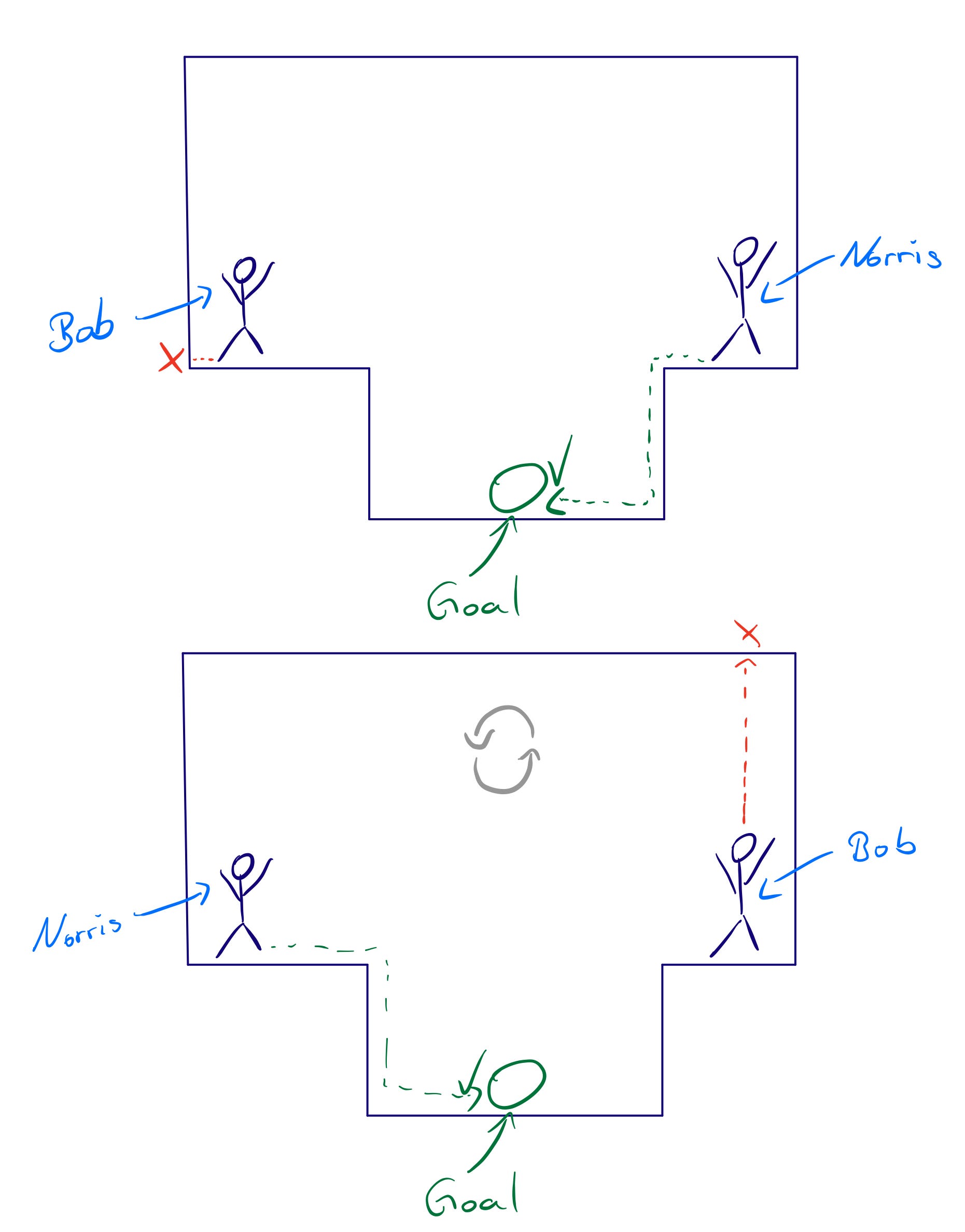
Now you can see, Norris seems to be better at his job, so Bob should learn from him. To let Bob learn from Norris in a supervised learning approach, collect samples from Norris actions in various situations and use supervised learning methods to train Bob to do the same. This won’t let him drive the car but at least he gets a jump-start in the walking skillset.
2. You are not in control of the environment
The previous case assumes you have full control over the environment. But often enough, agents act in an environment that is not under your control. Maybe you want to learn Norris’ skills without you being capable of controlling Norris or the states he is in. An example is the stock market. Norris could kick ass in the stock trading but that doesn’t mean his policy is better than yours.
If you can fully observe the environment, things get a little easier. You are now in an MDP, so you know what Norris saw before he made his choices. Assuming the future is like the past, if you observe 1000 actions (so many, to ensure we aren’t just copying a lucky idiot) performed by Norris and you plug his prior states into Bobs policy function, you can compare how Bob would have performed in his place. If he continuously outperforms Bob, he seems to have a better policy than Bob, so it can’t hurt to let Bob imitate Norris for a while with some cycles of back-propagation applied to Bobs NN.
When all approaches fail
If you cannot fully grasp the state Norris was in before he performed an action, it’s not really possible to compare your performance to his. But then it can be argued you cannot really *observe *Norris and that is the same problem we humans face. If I can’t observe how someone performs, I obviously can’t compare myself with them.
There are two situations however, that actually need to be avoided
Above, I talked about the stock market. Now, while normal people can trade at the stock-market without significantly changing the market through their actions, Jeff Bezos selling all of his Amazon stocks at once has a significant effect on the environment. If Bob has $1000 in stocks and tries to see if Bezos is a good person to imitate, he still cannot learn from Bezos. This is because, *even if Bob knew what to do in Bezos states and therefore if his policy was as successful as that of Bezos, his reality is a different one. *This is a situation where the other agent, while having the same goal (making money) is not a suitable role model, because he’s moving around in states, Bob will never even reach. So trying to learn from Bezos current trading options is not a smart move. Kids don’t learn walking by watching videos of Usain Bolt, and agents need to learn from agents which are better than them but not playing in a different league.
If collecting state-action pairs from other agents is an expensive endeavour, it might not be possible to regularly collect enough of this data to compare Bob to Norris and then evaluate whether to learn from Norris. We need a large amount of pairs however, if the $P(s’\vert s,a)$, meaning the probability of reaching s’ when performing a in s is not guaranteed. This is because otherwise, we might imitate someone who was merely lucky and who’s policy is not guaranteed to be better than ours.
The bottom line
I believe, the approach of letting agents learn from each other is an important one. There is already research that struggles with needing to retrain their agents for skills that other agents have already demonstrated, because they changed the architecture of their agents or because they used a different kind of neural network for the policy function. We cannot simply “copy a skill” from one agent to another, just as we cannot do so for humans, because their inner workings might be different. But we can let them observe each other and let them learn from each other.
A model therefore needs to be developed that can:
let agents determine if other agents are better than them and if so imitate them
Let agents learn by themselves and through imitation by alternating between classic reinforcement learning and supervised learning methods
In the future, it might also be interesting to teach agents to “teach”, meaning to purposely perform actions in a sequence that lets other agents observe and learn from them in an easier way. Such a “teaching agent” which already possesses the skill to walk could have a utility function that is dependent on the learning velocity of its students. The faster the students learn, the better does the teacher. Hence, it will try to perform the skill of walking in a way that let’s his students learn quickly.